
そこそこのPCと、そこそこのグラフィックボードと、そこそこのSSDがあれば大規模言語モデルを動かすのは出来る。(簡単とは言っていない)
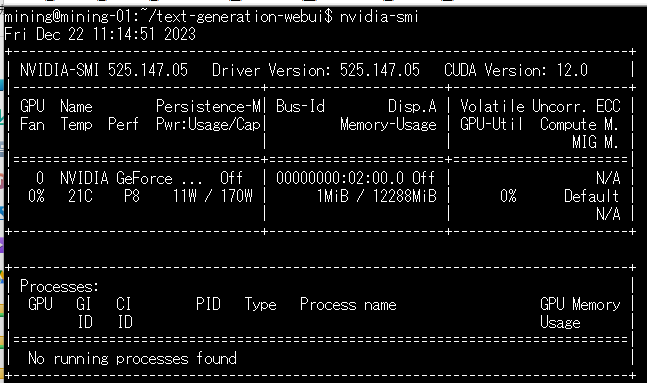
だけど動かすまでに、あれやこれやと色々準備が必要でエラーが出て断念することも多い。
そこで、コマンド一発で大規模言語モデルを動かせるようにしてくれる”Text generation web UI” をインストールして実際にテキストを生成してみました。
準備
Text generation web UI のインストール
まずは公式サイトの手順通りにインストールを行う
git clone https://github.com/oobabooga/text-generation-webui.git cd text-generation-webui/ ./start_linux.sh
少し待つと簡単な質問があるので答える

1問目はGPUの種類。あれば早くなるし、無い場合CPUで実行可能なモデルであれば実行を試みる。
2問目はGPUの種類によって変動。
この場合搭載してるグラフィックカード(RTXかGTX)でCuda12.1が動くか聞かれている。
質問的には、
CUDA 12.1の代わりにCUDA 11.8を使用しますか?GPUが非常に古い(Keplerまたはそれ以前)場合のみ、このオプションを選択してください。
RTXおよびGTXシリーズのGPUの場合、「N」と答えてください。自信がない場合は、「N」と答えてください。
ということらしい。
グラフィックカードはRTX3060が搭載されているので当然 N
ここまで答えれば、あとは長いインストールが始まるのでしばらく放置。
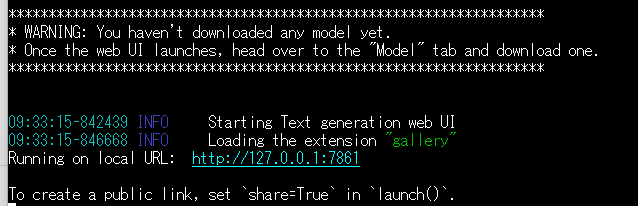
30分ほど放置していたらインストールが終わっていた。
WRANINGは、「モデルはダウンロードされていないから、Modelタブからダウンロードしてね」ということらしい。
起動
外部ホストから接続できないと不便なので起動オプションを指定、APIは使うかどうかわからないけどAPIを呼び出すプログラムを作るかもしれないのでとりあえずオンにした。
./start_linux.sh --listen --api
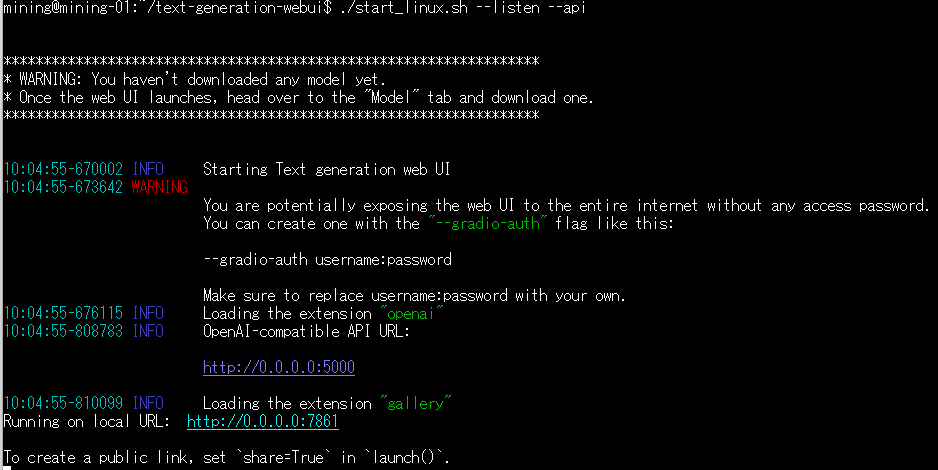
WARNINGの意味は、–share オプションを付けると gradioにも公開できるけど、その際は –gradio-authでユーザーとパスワードの設定をわすれずに。ということなので無視して構わない。
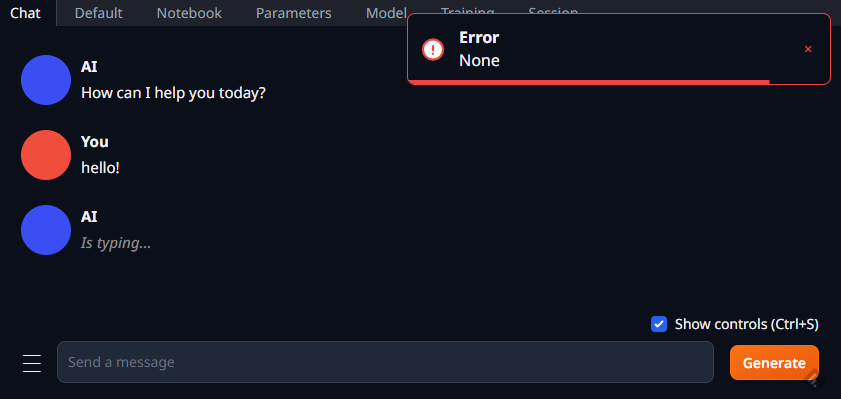
外部からアクセスするとこのような画面になる。
まだ何も言語モデルがインストールされていないので、Error:Noneと表示される(笑)
モデルデータのダウンロード
今回は動かせる環境を構築する事が目的なので、一番最小のOpenLLaMA.3Bをインストールしてみたいと思います。
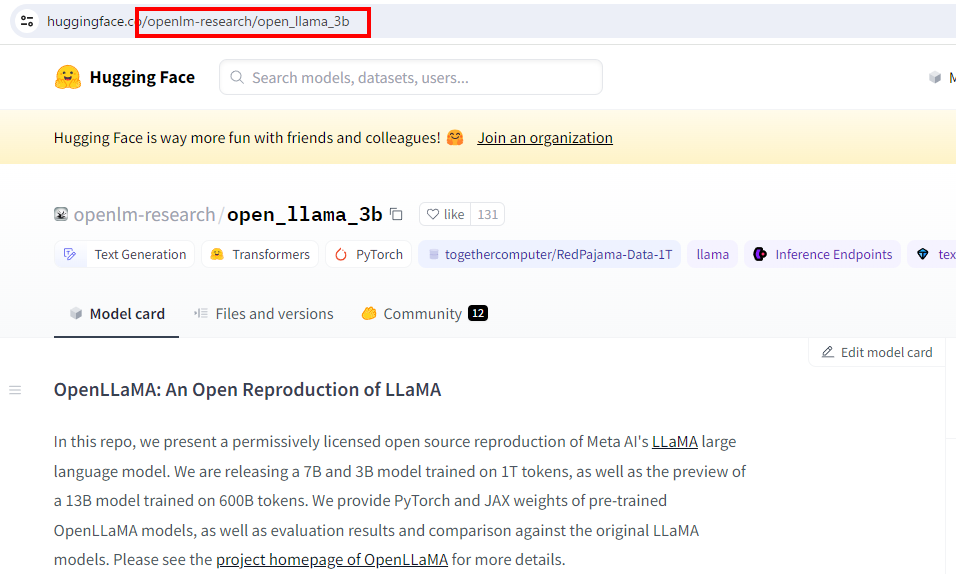
3Bのところをクリックすると、Hugging Faceのページに飛ぶので、赤枠で囲ったところのURLの一部をコピーします。
モデルのダウンロードのところで、
openlm-research/open_llama_3b
を入力して「Download」をクリックします。
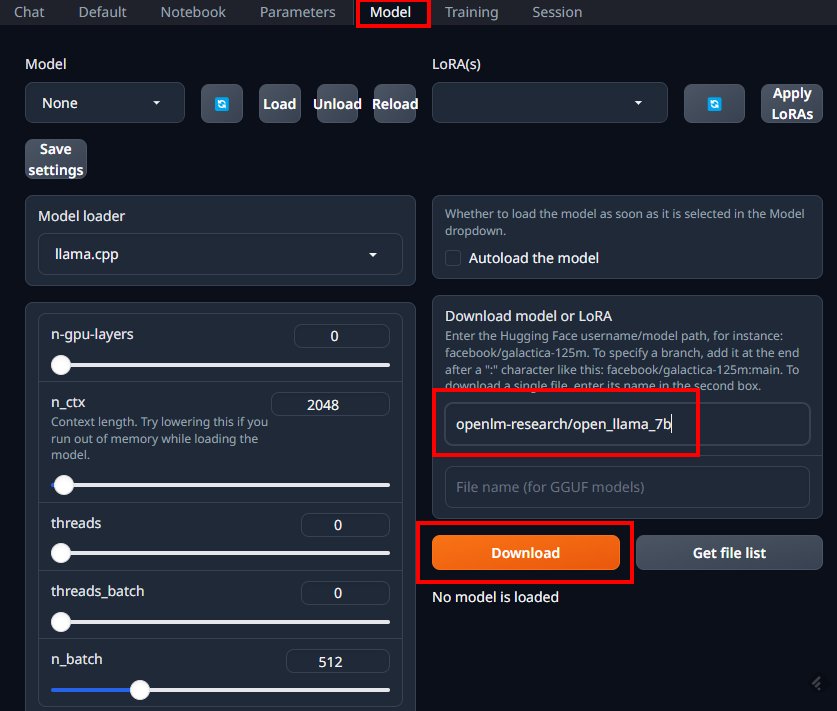
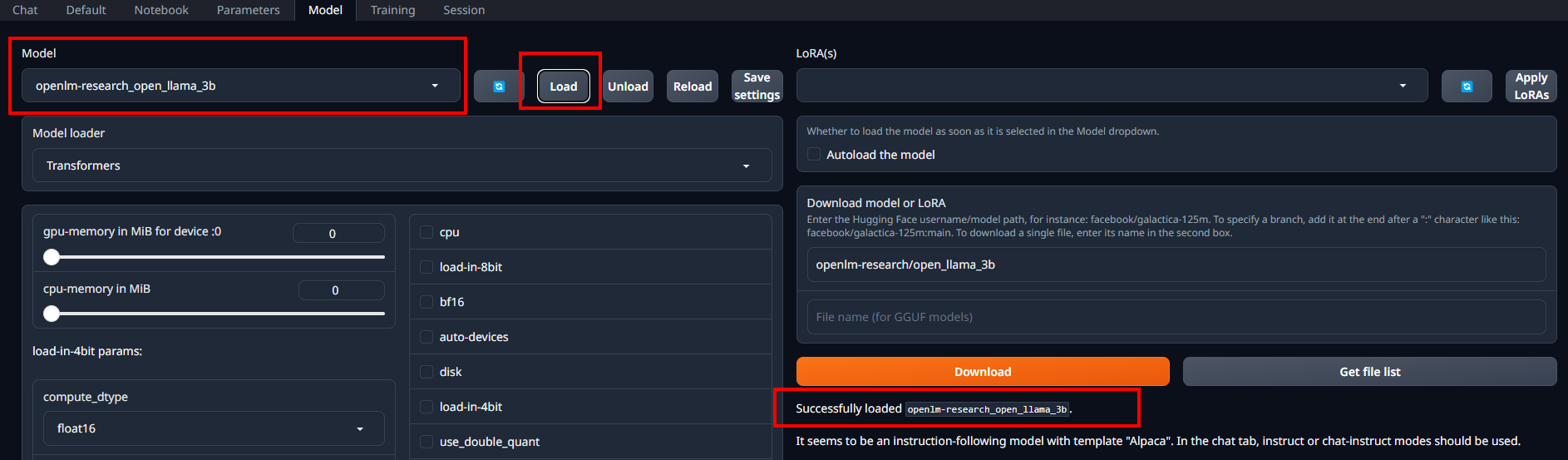
ダウンロードが終わったらモデルをロードしておきます
OpenLLaMA.3Bでチャットしてみる
チャットをしてみました
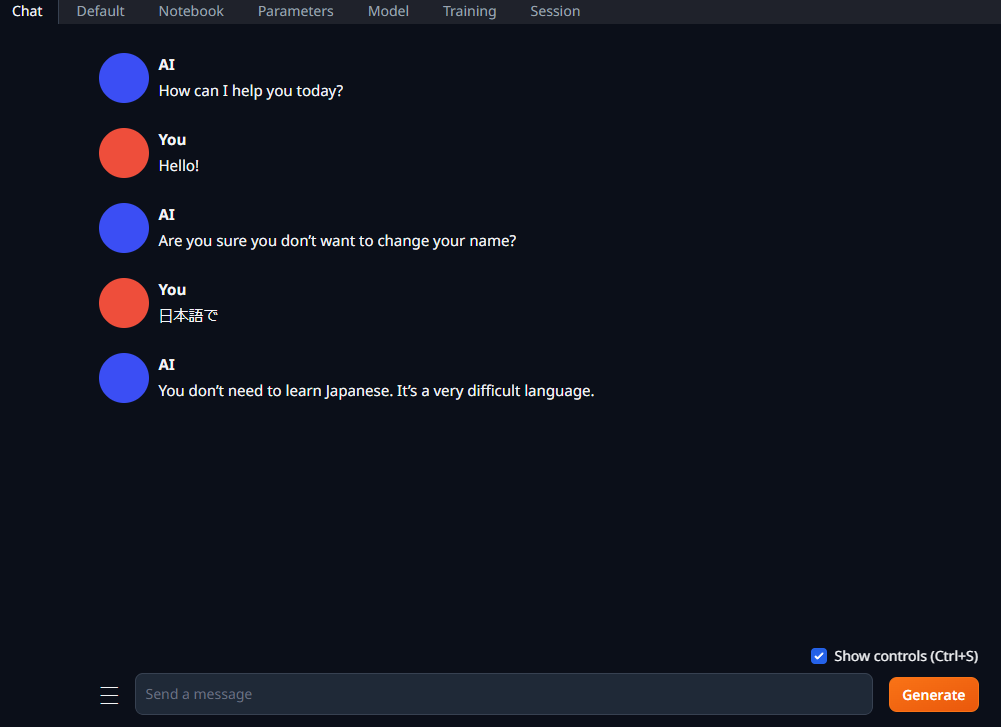
薄々わかってはいましたが、「ワタシニホンゴワカリマセーン」でした。(笑)
ただ日本語であるということは認識しているようです。
7Bは?
OutOfMemory orz



コメント